PDF 파일에서 원본 이미지를 추출하는 방법
소개
PDF는 가장 일반적으로 사용되는 문서 유형 중 하나입니다. 경우에 따라 PDF 파일의 이미지를 원할 수 있으며 이미지를 얻기 위해 PDF 파일에서 스크린 샷을 수행 할 수 있지만 해당 접근 방식을 사용하여 얻는 것은 원본 이미지가 아닙니다. 더 나쁜 것은 이미지가 많은 경우 많은 시간이 소요된다는 것입니다. 이 튜토리얼은 PDF 파일에서 원본 이미지를 추출하기위한 완벽한 솔루션을 제공합니다.. 소프트웨어를 설치할 필요가 없습니다. & 파일의 보안이 손상되는 것에 대해 걱정할 필요가 없습니다..
도구: PDF 이미지 추출. Chrome, Firefox, Safari, Edge 등과 같은 최신 브라우저
브라우저 호환성
- FileReader, WebAssembly, HTML5, BLOB, Download 등을 지원하는 브라우저
- 이러한 요구 사항에 겁 먹지 마십시오. 최근 5 년 동안 대부분의 브라우저가 호환됩니다.
작업 단계
- 먼저 웹 브라우저를 열고 다음 중 하나를 수행하면 아래 이미지와 같이 브라우저가 표시됩니다.
- 선택권 1: 다음을 입력 "https://ko.pdf.worthsee.com/pdf-images" 로 표시 #1 아래 이미지에서 또는;
- 선택권 2: 다음을 입력 "https://ko.pdf.worthsee.com", 그런 다음 열다 PDF 이미지 추출 수단 탐색하여 "PDF 도구" => "PDF 이미지 추출"
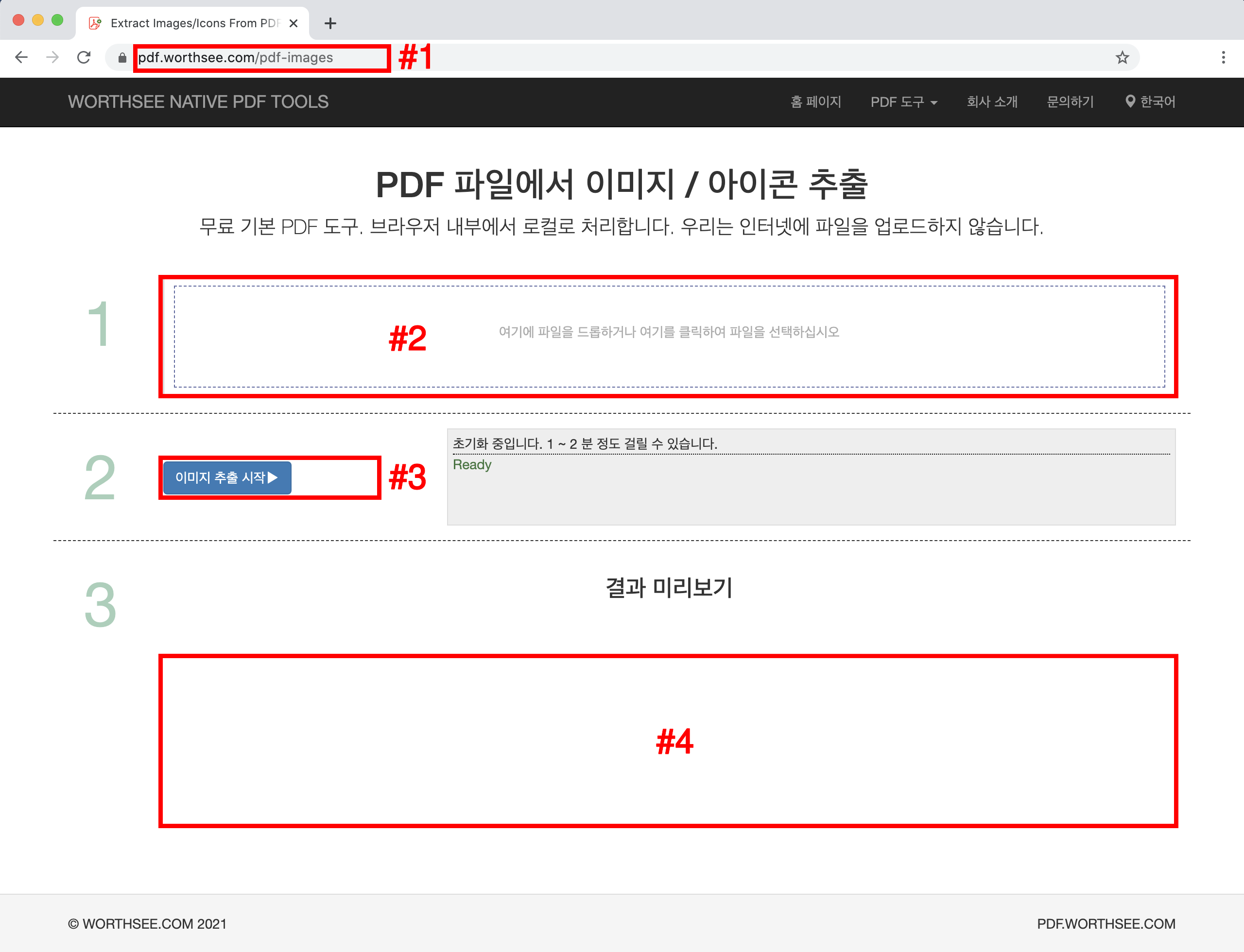
- 딸깍 하는 소리 지역 "여기에 파일을 드롭하거나 여기를 클릭하여 파일을 선택하십시오" (로 표시 지역 #2 위 이미지에서) PDF 파일을 선택하려면
- 파일을 해당 영역으로 끌어다 놓을 수도 있습니다.
- 원하는만큼 파일을 선택할 수 있으며 원하는만큼 여러 번 선택할 수 있습니다.
- 선택한 파일이 상자 아래에 표시됩니다. #2 미리보기
- 딸깍 하는 소리 단추 "이미지 추출 시작" (로 표시 단추 #3 위 이미지에서), 파일이 크면 다소 시간이 걸릴 수 있습니다.
- 이미지 추출이 완료되면 추출 된 이미지 파일이 이미지에 표시된 위치에 표시됩니다. #4 (위의 이미지와 같이), 간단히 클릭하여 다운로드 할 수 있습니다.
- 선택한 파일을 성공적으로 처리하면 다운로드 링크가 표시됩니다.
- 또한 압축 생성 파일을 ZIP 파일로 지원합니다. 생성 된 파일이 너무 많으면이 기능을 사용하여 zip 파일로 압축 할 수 있으므로 모든 파일을 여러 번 클릭하는 대신 한 번만 다운로드하면됩니다.